

















随着人工智能在我们日常生活中的普及,作为底层数据服务的数据采集标注行业也得到了充分的发展,数据采集是数据采集标注的第一个环节,也是人工智能数据训练的底层服务基础。市面上常见的数据采集方式分为多种种类,在技术角度而言,数据采集主要有客户端埋点和服务端埋点两种方式。
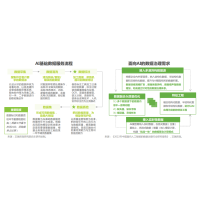
一、客户端埋点
客户端埋点主要通过在终端设备内嵌入埋点功能模块,通过模块提供的能力采集客户端的用户行为,并上传回行为采集服务端。常见的客户端埋点方式有3种:全埋点、可视化埋点和代码埋点。
1、全埋点
将终端设备上用户的所有操作和内容都记录并保存下来,只需要对内嵌SDK做一些初始配置就可以达到收集全部行为的目的。这也经常被称为无痕埋点、无埋点等。
2、可视化埋点
将终端设备上用户的一部分操作,通过服务端配置的方式有选择性地记录并保存。
3、代码埋点
根据需求来定制每次的收集内容,需要对相应的终端模块进行升级。
优略势分析
对于这3种埋点方式,企业可以根据实际业务场景来判断和选择。它们的优劣势对比如下。
1、全埋点适合于终端设计标准化且有统一系统接口的情形。它利用系统提供的事件捕获机制,在对象事件发生时调用埋点工具中的指定处理逻辑,对该事件相关的信息进行记录。这种方法的优点是不用频繁升级,在一次性验证并发布后,就可以获取终端的全量行为数据。当突然发现需要对某个对象进行分析时,可以直接从历史数据中找到所需的数据,而不需要再次进行数据收集。其缺点是数据存储、传输的成本较高,有些当前不用的数据也需要保留。
2、可视化埋点适合于需要考虑存储和带宽成本的情形,可通过后端配置来降低对象事件行为采集数量,实现机制和全埋点类似。其优点是发布后不需要频繁升级,成本比全埋点低,并且能够灵活配置;缺点是当需要对某一个对象进行分析,但发现其数据没有采集时,需要重新配置并等数据采集完成后再进行后续工作,容易影响业务进度。
3、代码埋点主要适合于终端设计非标准化、事件行为需要通过代码来控制的情形。其优点是灵活性强,针对复杂场景可以单独设计方案,对存储、带宽等可以做较多的优化;缺点是=-成本高,维护难度大,升级周期较长。
二、服务端埋点
除了客户端埋点,常见的线上埋点还有服务端埋点,即通过在系统服务器端部署相应的数据采集模块,将采集到的数据作为行为数据进行处理和分析。
服务端埋点常见的形态有HTTP服务器中的access_log,即所有的Web服务的日志数据。前面提到的客户端的3种埋点方式,常见的简化实现方案一般也会配合HTTP服务器中的access_log来落地,但有时为了更好地融合,会定制一些服务端的SDK,用于捕获服务端系统中无法通过常规访问获取的数据信息,如内部处理耗时、包大小等数据。
服务端埋点的优点很明显,当需要获取的用户行为通过服务端请求就可以采集到或者通过服务端内部的处理逻辑能获取时,采用这种方式来收集用户行为数据能够降低客户端的复杂度,避免一些信息安全问题。
但其弊端也很明显,有些用户行为不一定会发出访问服务端的请求,这种方式就无法采集这部分数据。因此,服务端埋点一般会和客户端埋点结合使用,相互补充,以完成全部目标用户行为的采集。https://www.data-baker.com


































